Who can determine the fate of ChatGPT? It seems that OpenAI can do it themselves.
After ChatGPT’s explosion in the field of technology, people have been discussing what the “next step” in AI development will be, and many scholars have mentioned multimodality. We didn’t have to wait too long. Today, OpenAI released the multimodal pre-training large model GPT-4.
GPT-4 has achieved a leap forward in the following aspects: powerful image recognition capabilities; a significant increase in the limit of text input to 25,000 words; significant improvement in answer accuracy; and the ability to generate lyrics and creative texts with style variations.

“GPT-4 is the world’s first advanced AI system with high experience and strong capabilities, and we hope to soon push it to everyone,” said an OpenAI engineer in the introduction video.
It seems that OpenAI wants to end this game in one fell swoop. They have not only released a paper (more like a technical report) and a System Card, upgrading ChatGPT directly to the GPT-4 version, but also opened up the API for GPT-4.
In addition, a Microsoft marketing executive was the first to say after the release of GPT-4: “If you’ve used the new Bing Preview in the past six weeks, you’ve already seen the powerful features of OpenAI’s latest model.” Yes, Microsoft’s new Bing has already used GPT-4.
GPT-4 is a large multimodal model that can take both image and text input and produce accurate textual responses. Experimental results show that GPT-4 performs at a level comparable to humans in various specialized tests and academic benchmarks. For example, it passed a simulated lawyer exam and scored in the top 10% of test-takers, while GPT-3.5 scored in the bottom 10%.
OpenAI spent six months iterating and adjusting GPT-4 using adversarial testing programs and lessons learned from ChatGPT to achieve the best results ever in terms of authenticity, controllability, and other aspects.
Over the past two years, OpenAI has rebuilt the entire deep learning stack and designed a supercomputer from scratch with Azure for its workloads. A year ago, OpenAI first attempted to run the supercomputer system when training GPT-3.5, and subsequently discovered and fixed some errors and improved its theoretical foundation. The result of these improvements is that GPT-4’s training runs with unprecedented stability, allowing OpenAI to accurately predict its training performance ahead of time, making it the first large model to achieve this. OpenAI says it will continue to focus on reliable scaling, further refine methods, and help achieve stronger predictive performance and future planning abilities, which are crucial for safety.
OpenAI is releasing GPT-4’s text input functionality through ChatGPT and APIs (with a waiting list). For image input functionality, OpenAI is partnering with other companies to increase its availability.
Today, OpenAI also open-sourced OpenAI Evals, a framework for automatically evaluating AI model performance. OpenAI says this is to allow everyone to point out flaws in its models and help improve them further.
Interestingly, the difference between GPT-3.5 and GPT-4 is subtle. Differences emerge when task complexity reaches a certain threshold – GPT-4 is more reliable, more creative, and able to handle finer instructions than GPT-3.5. To understand the difference between these two models, OpenAI conducted experiments on various benchmarks and some simulated human-designed exams.
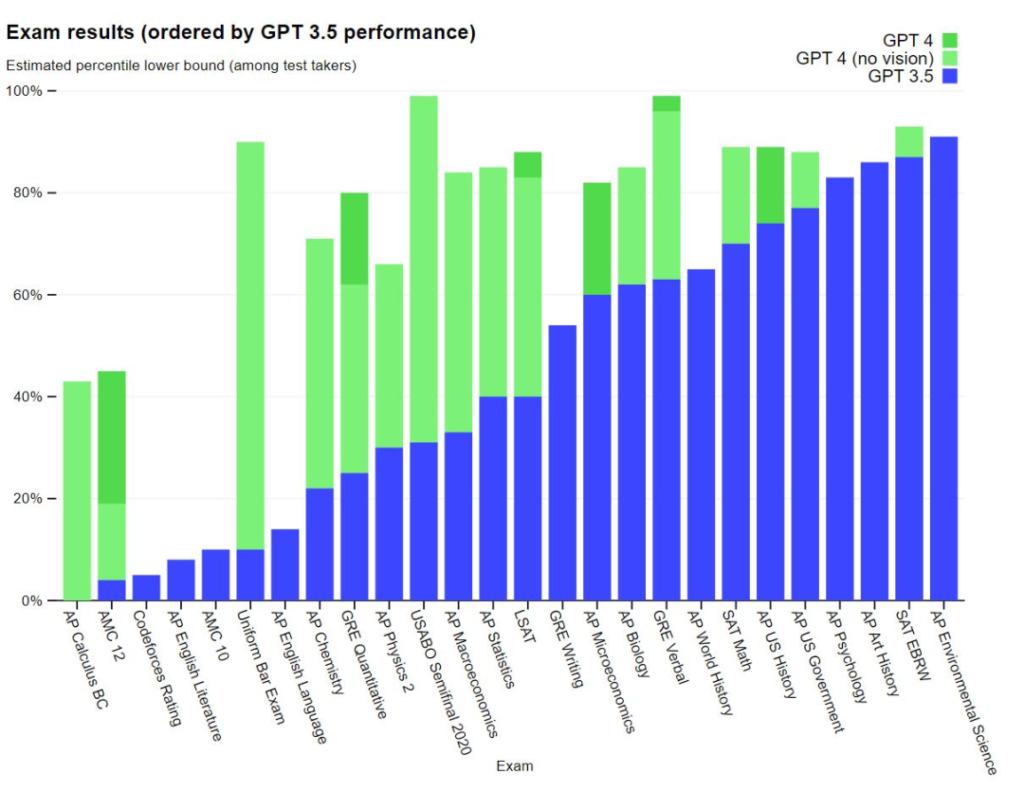
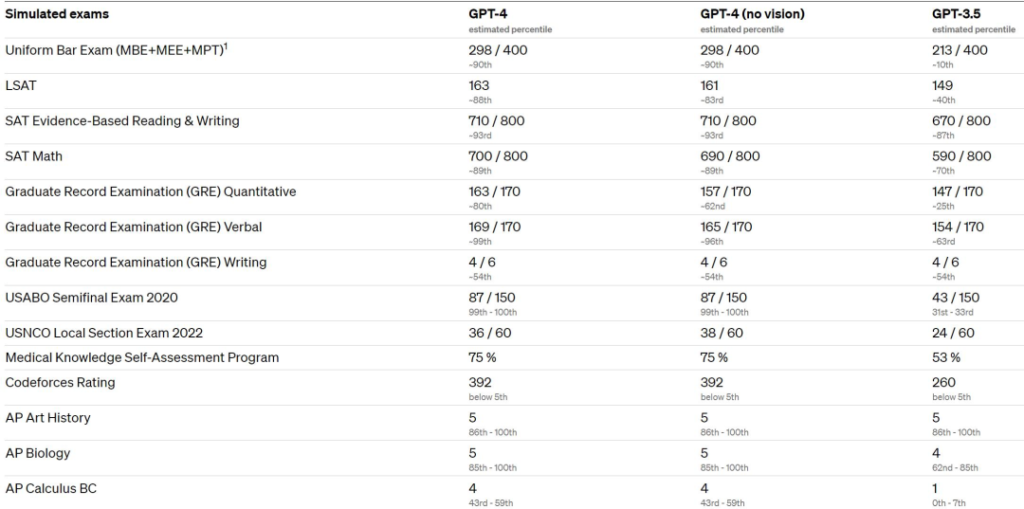
OpenAI evaluated GPT-4 on traditional benchmarks designed for machine learning models. The results showed that GPT-4 significantly outperforms existing large language models, as well as most state-of-the-art models.
OpenAI also uses GPT-4 to help people evaluate AI output, which is the second phase of OpenAI’s strategy. OpenAI is both a developer and a user of GPT-4.